
What I have learned from web scraping the Coast website
Overview
Web scraping (the automatic collection of data from a website through programming code) is a commonly cited skill of a data scientist. Last year I was looking to develop these skills at the same time as wanting a new dress for an upcoming wedding. There was one particular dress I liked, made by Coast, so I decided to try to learn web scraping using the Coast website as a test.
Previous experience
Although I hadn't done any web scraping before, I had collected data from APIs (Application Programming Interfaces), and I had done a couple of short courses on html and CSS through the CodeAcademy website for free. I think that knowing a little about html was very useful and would recommend others start with this before web scraping.
I then searched for online resources about how to learn web scraping. I'm now unable to find the resource I used but there appear to be lots of other suggestions and resources online.
Other options to writing code
I am aware that so-called 'point and click' web scraping exists (such as through import.io) which don't involve any programming, but I'm a data scientist so I wanted to write code and find out how it all works.
Ethical web scraping
In my learning I ensured that I was adhering to the terms and conditions of the Coast website (as some websites don't allow web scraping). I also ensured that I was only collecting a minimal amount of information to ensure that I wasn't placing a heavy burden on the website. I think this is really important. There are other things that can be done such as respecting the robots.txt protocol (which lists what pages on a website you can't web scrape) and ensuring a specific time lapse (such as 5 seconds) between accessing different pages.
The web scraping
I started by looking at a particular dress on the website and trying to programmatically obtain certain information about the dress (name, colour, price and stock availability for different sizes) by using the Python package Beautiful Soup and ascertaining which html tags were relevant for these different bits of information.
I then generalised this by picking up a list of urls (one for each dress) from the Coast website dresses page and iterated over the urls to get the relevant information for each dress, converted this to a pandas data frame and eventually outputted it to a csv file for analysis in R. I've re-run this web scraping four times so now I have a time series of dresses from the website during 2016 and 2017. When I re-run it, I usually have to slightly update the code as the website has changed structure.
Analysing the dresses information
I analysed a variety of information such as colours, stock availability and price, and have the following observations:
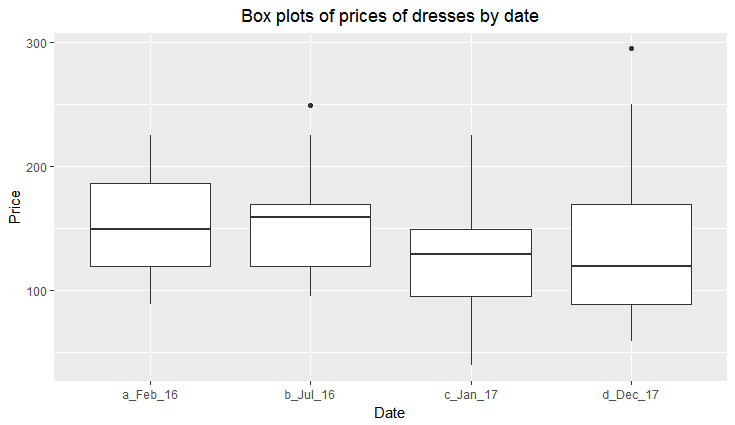
The average price of a dress on the website is between £100 and £200, but the median price is coming down over time
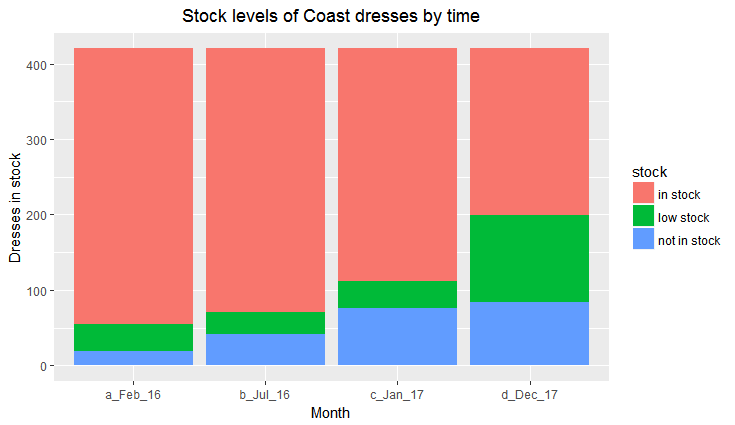
An increasing number of dresses by size are either not in stock or have low stock over time. In this chart there is one count per dress / size so each dress is counted seven times (once for each of size 6, 8, 10, 12, 14, 16 and 18)
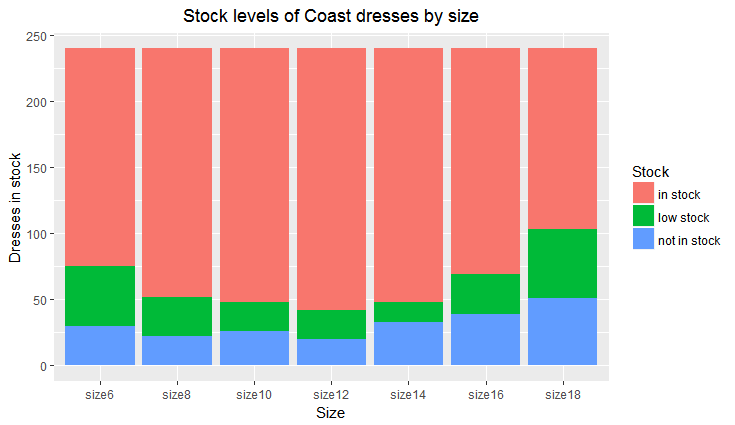
There's more chance of finding a dress having low stock or not being in stock in the smallest sizes (6 and 8) and the largest sizes (16 and 18). The middle sizes (10, 12 and 14) have the greatest stock availability
Get the code
My code is available on Github and I always welcome comments or suggestions for improvements.