
How to deal with data that is too big to handle
The problem
Sometimes we need to analyse data that is too big to handle using traditional methods. This might be data from sensors, from social media or financial transactions. Typical laptops have 8GB or 16GB of memory. However, this does not mean that if you have a laptop with 16GB of memory that you will be able to analyse a dataset of size 16GB because your laptop will have a memory overhead of at least 25% to 50%, depending on the task you are doing. So what can we do when we need to analyse a dataset which is much bigger than 16GB, say 150GB in size?
The solution
Parallel or distributed computing has been developed to solve this so-called out of memory problem. Analytical jobs are split over multiple cores of a laptop and undertaken in parallel based on the map reduce framework which was developed in 2004 by Google. The diagram below provides an example of this by taking three lines of words and illustrating how we would count the instances of each word using this framework.
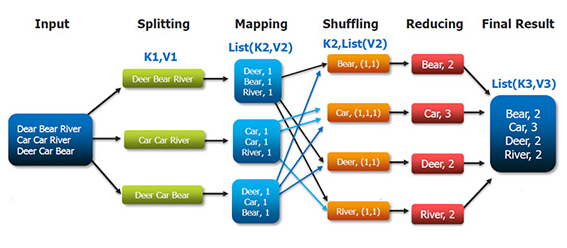
The lines are split, mapped to a list counting the instances of words, then reduced by summing the instances across the splits.
The Python package dask and R package parallel have been developed to deal with this situation. They are lightweight because they only involve installing the packages themselves. However, these packages lack some of the features we may want to use such as machine learning.
When people have these out of memory problems, Spark is a more popular choice than these packages. It builds on the map reduce framework and can be programmed using Python (using the pyspark package) or R (using the sparklyr package).
Some people use Spark on large clusters of computers, but you can also install and use Spark locally on your laptop to analyse that 150GB file. To do this you will also need to install the programming languages Scala and Java, and add these (and Spark) to the environment variables. Instructions for how to do all this on Windows is here).
However, once installed, it ran twice as fast as dask for importing data, and much quicker for other operations. Spark also supports a much wider range of functionality than the dask and parallel packages.
Is Spark best used through R or Python?
Spark can be used through both R and Python but Python is more commonly used, partly because pyspark has more functionality than sparklyr. This also means that the community of sparklyr users is smaller, and troubleshooting problems can be more difficult. For example there are about 20,000 questions tagged with pyspark on Stack Overflow, compared to just 600 tagged with sparklyr.
Examples
Let us presume we have a CSV table of names where we need to count the number of people of each name in the table. The text below illustrates how to do this using R and Python.
| Name |
|---|
| Susan |
| Bob |
| Tony |
| Susan |
| Susan |
Example using Python
# Load packages
from pyspark.sql import SparkSession
from pyspark import SparkContext
# Connect to the local spark instance using as many threads as on your machine
spark = SparkSession.builder.master("local[*]").appName("test").getOrCreate()
# Read in a CSV
my_data = spark.read.csv("/path/to/csv/my_data.csv", header=True)
# View first five rows of CSV
my_data.head(5)
# Count the number of instances of each name and show this summary table in the console
my_data.groupBy("Name").count().show()
Example using R
# Import package
library(sparklyr)
# Connect to the local spark instance
sc <- spark_connect(master = "local")
# Read in a CSV
my_data <- spark_read_csv(sc, path = "/path/to/csv/my_data.csv", header = TRUE)
# Count the number of instances of each name and show this summary table
# Note that a lot of manipulation uses dplyr syntax
my_data %>% group_by(Name) %>% View()